Everything is an executable
10 November 2023 - 11:00
Everything is an executable
In the early 1990s I started programming in what I imagine was a somewhat reverse way. Instead of starting at a high-level language such as BASIC and then slowly moving through Pascal towards C, I started off in x86 assembly language. This was due to my interest in real-time graphics on the 386s of that time and the fact that the community around these demos (the Demoscene) was focused on using assembler.
Some of the first programs I wrote on MS-DOS using Turbo Assembler were not of the typical EXE type but files that were also executable back then: COM files. These were probably the most basic type of executable possible. There was no header, no metadata, no footer, just a translation of the assembly language instructions in the source file to a stream of opcodes directly executable by the Intel processor. This was a great feature as it made debugging and understanding opcodes easy, there was nothing to wade through to get to your code.
These days, executables are a lot more complex and we don’t have those COM files anymore. EXE files still exist in the form of Portable Executables on Windows, along with other executable file formats such as ELF on Linux. But an EXE file contains a lot of additional stuff next to the compiled code. For starters, multiple executables to run on different platforms (in the simplest case this boils down to the Windows program and a small DOS program that says “Sorry this only runs on Windows”, but PE still supports other architectures). But apart from that, it contains a bunch of metadata that the operating system uses to load the code into memory and map its dependencies.
Execution is risky
Those fat binaries are still what we generally recognize as an executable, along with the risks they pose. Once you decide to execute them and they pass some basic checks by the operating system, the compiled code is loaded and the operating system tells the processor to run it. The risks here are that even though modern operating systems impose all kinds of security boundaries and checks, the running code has a pretty big attack surface to explore. It has access to large amounts of API and external library calls compounded by many possible arguments it can pass to them.
And so that’s why we tend to worry about running executables. We use virusscanners to determine if an executable contains patterns recognizable as part of known malware. We use hashes and other cryptographic tools to make sure executables are not tampered with. We even analyze entire software supply chains in order to find libraries and other executable parts we don’t trust. All based on the realization that if some piece of code manages to hijack a computer at a crucial position everything may become compromised.
Indirect execution
But are executables so much different from other files when it comes to the risks associated with using them? There are also many cases of indirect code execution. Or rather, almost every other file has many instances of indirect code execution associated with it. First the most obvious: executables targeting virtual machines, such as Java and .NET. Even though these are generally regarded as executables in the traditional sense and handled in a similar way, their structure is interesting as a bridge towards all other file types.
Java applications packaged in JAR files are actually compressed ZIP files containing a bunch of associated files, some of them containing metadata and others (almost) executable code. But those CLASS files containing code are actually made up of more metadata and code compiled to target a non-existing (virtual) machine, which needs to be interpreted in order to actually be run (although modern interpretation may consist of compilation and direct execution, complicating everything even more).
My point is not that a Java application is an executable too, but rather that there is execution in many of its aspects not directly related to its (virtually) executable code. The processing of practically any type of file boils down to executing one or more virtual machines and directing them to execute instructions provided by some outside source (the input file). For example, let’s have a look at what happens when you open a PNG file, as in when you double-click on it in order to show the picture it represents on your screen.
Code is data, data is code
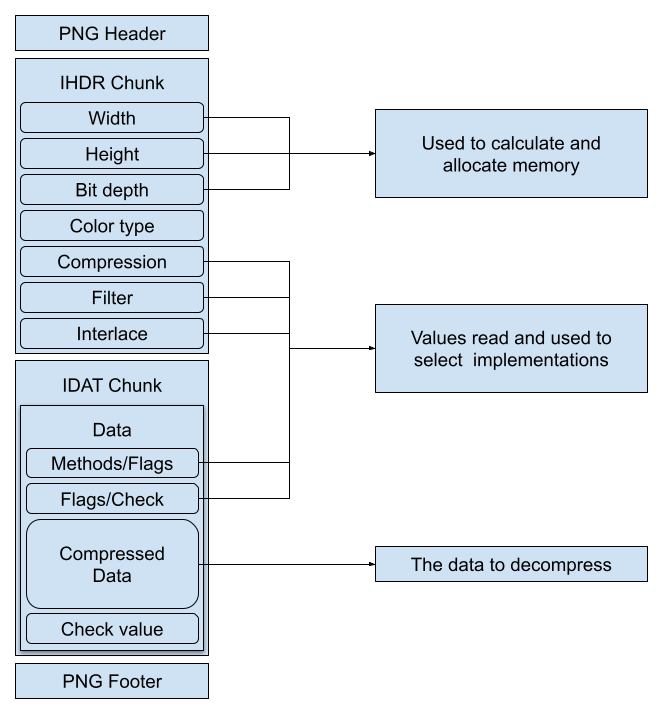
First, a description of what a simple PNG file contains. PNG is a very well-designed file format and a simple instance of it contains just a header (eight bytes, 0x89504E470D0A1A0A) and a footer (twelve bytes, 0x000049454E44AE426082, which is actually a fixed instance of an IEND chunk). Between those are at least two data structures: an IHDR chunk with typical image-describing metadata and an IDAT chunk that has a compressed version of the actual pixels. Each data structure in PNG consists of a length field, a name, the payload and a checksum. This makes it easy to verify that the file is not corrupt or truncated.
First, IHDR contains only metadata: the amount of pixels and aspect ratio (width and height), the amount of bits for each pixel and how this information is mapped (bit depth and color type) and how to interpret the pixel data (compression, filtering and interlacing methods). As with most standards it was developed with the expectation of much more extensibility than eventually was necessary: there is only a single compression scheme and only a single filtering method and none were added since 2003.
Next is IDAT which contains the actual pixel data, but is compressed using the Deflate algorithm from ZLIB. So while from the PNG perspective its contents is just data, the actual data has more structure, this time defined by another standard, which also needs to be parsed. Once the data is decompressed, PNG defines a bunch of filtering methods to reconstruct the actual pixel data by combining several values of near pixels.
Is all this safe?
So opening a PNG file means you are telling your computer that you are fine with it allocating lots of memory and running a bunch of parsers and letting the values in the file determine how these are called. If the size values are wrong or extremely large, this may result in an attempt to allocate a too large amount of memory, which may have unknown consequences for the application. Lots of things may break or leak if we run decompression, filtering or interlacing code with dodgy parameters or malformed data.
Looking at a picture doesn’t really conjure up this idea of running the risk of executing an unknown app or installing some dodgy service. But opening practically any file on everyone’s computers and phones comes down to running lots of code on the machine using parameters dictated by the file. Combine this with the messy state most file format encoders are in and it’s maybe time we cleaned all this up!