Who fixes your data files?
27 September 2023 - 11:30
Who fixes your data files?
After 20 years of writing software to automate digital forensics investigations I can say that most developers don’t take writing binary data files seriously. Binary data is practically everywhere except for the contents of text-based files such as source code or text-based protocols such as HTTP. Everything else needs a piece of software to read it, reconstruct its data structure and then interpret each value. Developers tend to use terms like (un)marshalling, (de)serializing and encoding/decoding for these things.
In essence though, this means that decoding looks a lot like what an interpreter does. So in a way, even a file such as a JPEG image, a PDF document or a ZIP archive is a kind of executable too. This explains why there are often security exploits that revolve around specially crafted or malformed data files.
A big part of forensics is getting as broad a view as possible of all the evidence in a case. Especially in digital forensics, a lot of work comes down to analyzing large amounts of binary data that might be relevant to a case. To this end, tools are used to parse files, collect traces and assemble models and relationships.
Sometimes this comes down to just indexing all the names in a bunch of documents, but in larger cases entire social and messaging graphs may need to be reconstructed. And not just from the top-level messages visible in their respective apps, but from the locally stored copies of databases, including their temporary files or even transaction logs. This includes dealing with files that have been truncated, partially overwritten or otherwise broken. But much more interestingly, when you attempt to parse these files you get a view of the evolution of the developing organization.
File formats are a mess
File format specifications are rarely created and then never touched again. Instead, they evolve as new types of data are added and existing records are extended or changed. For example, some of the older record types in serialized files will contain non-y2k compliant timestamps, while newer ones will take extra space to handle this. This shows you how the developers chose to deal with it: whether they rewrote everything or just changed things going forward, opting to just assume all the old-style timestamps were from the previous millennium.
It’s also possible to discern trends in software engineering through the evolution of these long-existing file formats. The older parts of the specification might use some clever type of string to represent text, such as a string value preceded by a fixed amount of bytes to denote the size. Then at some point, usually when the application goes international, these strings may support either 8-bit ASCII or some fixed 16-bit UNICODE-like type, or both. But in later situations the developers may opt to make the parsing easier and just assign fixed sizes to the locations where strings are stored, marking unused data with zeroes. And eventually everything turns into UTF-8, or at least something resembling it.
But the specification is only half the story. It’s almost impossible to find an implementation of any non-trivial file format, either a writer or reader, that entirely adheres to every corner of the specification. So specifications are usually a mess of legacy bolted onto many good and bad ideas, while the actual implementations are similarly constructed. Where does this leave you as a developer trying to parse a file?
Every opportunity is also a risk
This might seem like a gold mine for digital forensics, but in practice it just creates headaches through many exceptions in parser code. And endless combinations of if/else-constructs in code dealing with external inputs is the perfect place to find ways to compromise a system. This doesn’t matter for digital forensics, since these tools should only look at dead systems in sealed off environments. But how does this relate to all the binary data files that get moved around on the internet all day and parsed by software?
Analyzing problems in handling inputs is a typical case for Application Security Testing (AST) tools that bring many types of static and dynamic analyses to pinpoint problems. These tools are good at finding the spots in your code where you blindly use a value from an outside input as a size argument to a memory allocation call. Or where you assume that the only combination of flags that will ever be present in a file will be those you’ve created a mapping for in your pointer table.
But how deep can you analyze all this effectively? A case where a value in a file leads directly to an argument in an API call seems reasonable to detect as a risk. But many file formats and protocols have very hairy rules about the order in which data structures are supposed to be written to a file. For example, about what the existence of some piece of data somewhere in the file means about some other parts of the same file, etc. AST tools tackle this by moving from static analysis to dynamic analysis, to analyze your software’s behavior in actual scenarios. And then there are approaches such as fuzzing, that just attempt as many combinations of different inputs as possible in order to find a weakness in the handling of them.
Flipping and reducing the risks
To improve the quality and security of common types of files that move around the internet, a dual approach is needed: improve the parsers, but also improve the files. In this context, the anti-virus space has come up with a constructive approach: Content Disarm and Reconstruction (CDR). Instead of scanning files for known bad patterns and capturing files that have a match, CDR transforms the files to make them safe to use instead.
This approach has multiple levels of sophistication, where the base level is just taking screenshots of your documents and pasting them into a new file. More advanced tools actually parse each file completely, extract the content and then build an entirely new file of the same type. The goal here being that such a transformation removes all non-standard cruft that is typically used in malware attacks.
Existing CDR solutions are deployed in corporate environments. As a plug-in for a mailserver to clean attachments or as a web-proxy to clean images and fonts before they are sent to the requesting browser. But it makes sense to deploy such a solution much closer to the source as well. For example, in a CI/CD pipeline where website and app images, documentation files, additional archives and any other binary data assets pass through along with a project’s source code.
Cleaning your own files too
This approach doesn’t solve the handling of outside data files, but it does prevent an app or website from unintentially spreading a lot of problematic data. First of all, data files originate from many different sources, each of which may be compromised. Even the tool you use to optimize your images or documents can be tricked to include something dangerous.
Apart from malware and other attacks, data files sometimes contain a lot of often unintended privacy-sensitive information. A tag containing the name of the person who created the file, or the location where the file was created. In addition, many editors don’t modify documents such as PDFs to change the content, they just append a change to the end of the file and let readers handle the updates. This may be considered a feature of the file format, but people modifying agreements probably don’t always want to distribute their edit history.
And finally, it seems that most applications are overly focused on the second part of the Robustness Principle. Being liberal in what you attempt to process as a valid piece of data works well in a research environment where everybody tries to help each other. In the current world of constant cyber attacks, perhaps it’s also important to focus on the first part about being conservative in what you send. Distributing only minimal files adhering to the strictest interpretation of the related standard can go a long way to prevent problems.
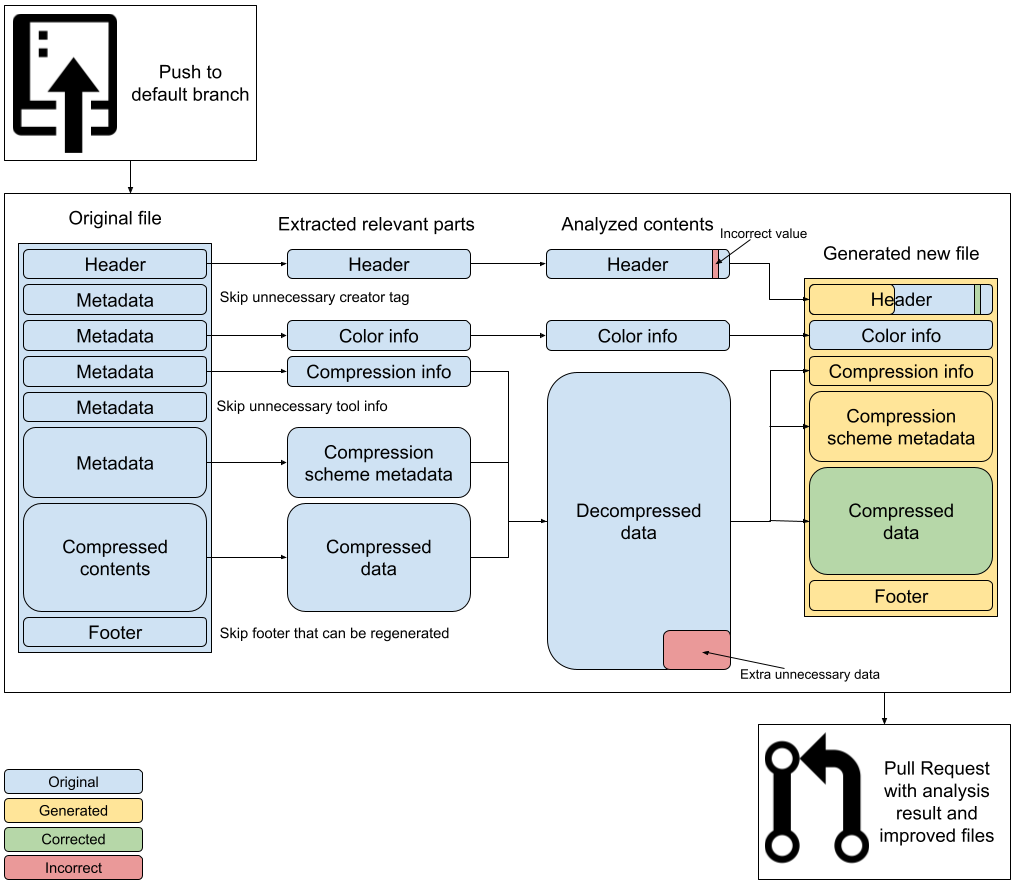
How to trust the cleaner
What is needed to make this work is the following: A tool that integrates in the CI/CD pipeline in order to ensure that all data files pushed into a project are analyzed and if necessary, transformed. But instead of just cleaning files, it needs to be transparent about the changes it proposes. To make this work, each change should be in the form of a change proposal, like a pull request for Git. It should clearly document and show what things were detected and how these were modified. This way, the project is not exposed to the tool’s own problems or supply chain risks.
As you may have guessed, this is what we’ve been working on: Binfix for GitHub. An experimental version is available, free to use on public and private repositories for users and organizations. It’s a work in progress but we’ve decided to just launch early and collect feedback on how to continue development on this.
The app right now analyzes all pushes to the default branch of each repository it’s installed on. When a supported file type is detected, which are currently PNG (Release Candidate), JPEG (Beta) or PDF (Alpha), the file is analyzed and transformed if deemed necessary. A checkrun is added on the commit that links to the analysis report and possibly a Pull Request.
Apart from extending support for the current file types, we will soon add additional file types and transformation. In addition to that, we would like to build a full-featured binary data diff that GitHub currently lacks, to make it even easier to assess the changes that Binfix proposes.
Feel free to try it out and let us know what you think!